微架构瞬态执行攻击
什么是瞬态执行
为了提升 CPU 的运行效率,现代 CPU 设计的时候会把微指令的顺序重新排列,或者在遇到分支的时候预测执行。但是这些指令不一定是有权限的,或者这个分支不一定会被执行,因此,芯片会丢弃所有的预测性结果并运行另一个分支或者触发异常。但是这些指令确实执行楽,所以缓存中就会载入越权访问的数据。
缓存测信道怎么泄露在缓存里面的数据
FLUSH+RELOAD
预备知识
页共享
进程间共享内存主要有两个目的,首先是进程间通信,然后可以减少内存占用。
减少内存的方式比如:
页面感知(content-aware)共享,相同的页面由加载的页面内容的磁盘位置标识。进程间共享可执行文件和共享库的代码段。
基于内容的页共享,也叫内存重复数据消除(memory deduplication),是一种更主动的页共享机制。系统扫描活动的内存,识别并合并有相同内容的页。
但是对于不相关的进程的共享页面,这些共享页面仅仅是为了节省内存引入的,操作系统需要保护在不相关进程间共享的内存页,防止恶意进程修改共享页。把共享页设置为写时复制,写入共享页时会陷入,OS 会获取 CPU 控制权,复制共享页内容,再映射到进程的地址空间。
这里存在测信道——写时复制引入的延迟会导致信息泄露。
cache 结构
三级缓存
下图是一个典型的存储器层次结构,使用了三级缓存。
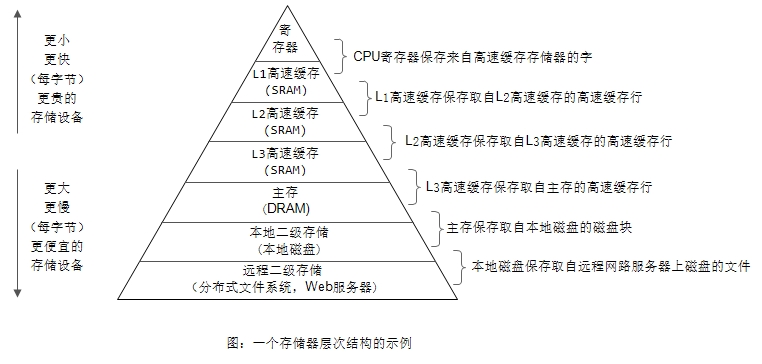
他们之间的速度差距:

L3 Cache和L1,L2 Cache有着本质的区别。L1和L2 Cache都是每个CPU core独立拥有一个,而L3 Cache是几个Cores共享的,可以认为是一个更小但是更快的内存(memory)。
haha 又来学计组咯
组相联缓存
缓存块被分组,每一组只能在一组特定的缓存中。比如:有8个单元可用于存储缓存所关联的缓存块,从而形成一个8路关联的组(8-way associative set)。
直接映射
一个主存块只能拷贝到cache的一个特定行位置上去。
容易冲突之后被替换
全相联映射
主存的一个块直接拷贝到cache中的任意一行上。
线路复杂,成本高,速度低
组相联映射
组相联映射实际上是直接映射和全相联映射的折中方案。
主存的某块只能映射到Cache的特定组中的任意一块。
LLC
Intel LLC 的一个重要特性是包容性(inclusive),即 LLC 包含所有存储在低级缓存中的所有数据的副本。因此从 LLC 中刷新或逐出数据也从其他缓存中移除数据。